
Fast, Cheap, or Smart: Pick Three? The GPT-4.1 Promise
Latency vs. Intelligence vs. Price, context window accuracy, and agentic workflows

Another week, another model announcement, and this time directly related to AI-assisted coding! GPT-4.1. Let’s dive in (see part1, part2, part3 for previous explorations).

First, I tried cheaper GPT-4.1 mini as a potential replacement for DeepSeek. It seemed decent at planning, but the coding was awful. It lacked agency and made way too many mistakes. Sure, it’s practically free but if you spend more time correcting and fighting with it, how much is it really costing you?
I quickly moved on to the “full” 4.1 and was immediately impressed by its thinking, snappiness, and general ability to get complex things done correctly. Speaking of snappy, we’re finally entering an era of talking about latency in addition to intelligence! I love that OpenAI released 4.1 with this graph:
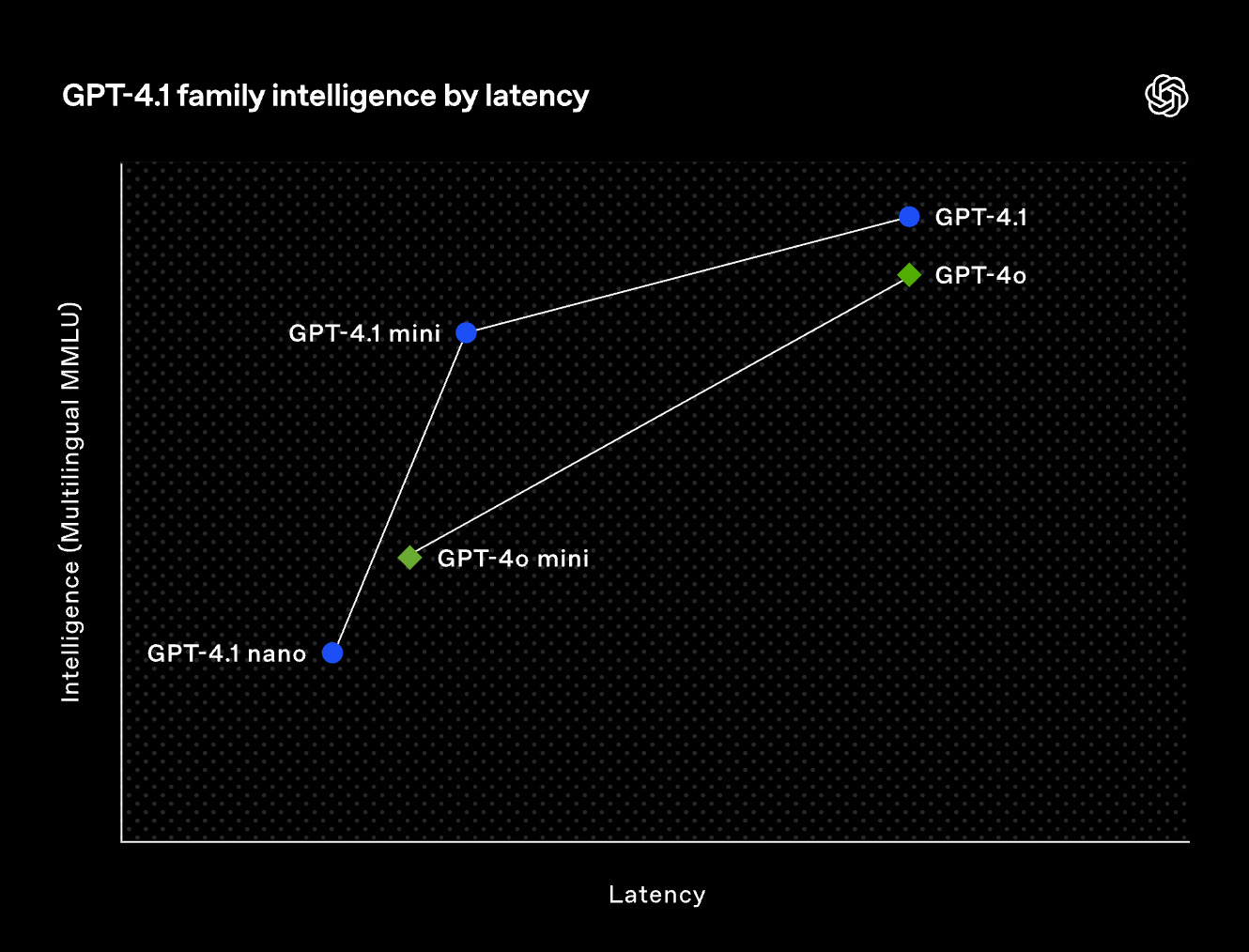
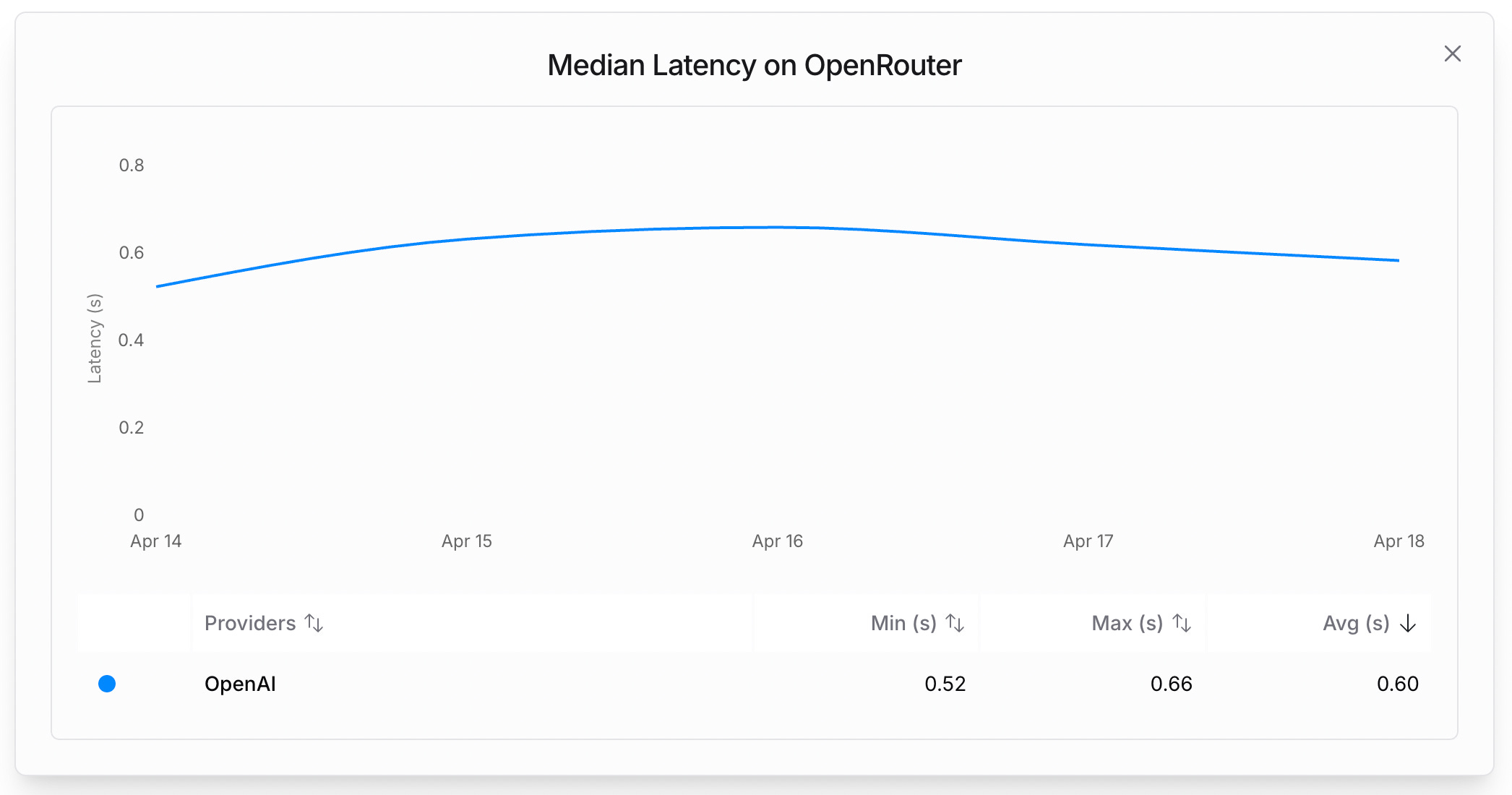
Neither Sonnet 3.7 nor Gemini 2.5 Pro announcements ever talked about latency, yet it’s a pretty crucial aspect when iterating quickly with an AI assistant. If we compare their stats on OpenRouter (a popular aggregator used by users of Cline, Roo Code, etc.), Gemini is averaging ~10-15sec, Sonnet ~1.5sec, and GPT4.1 is at a stunning 0.6sec.
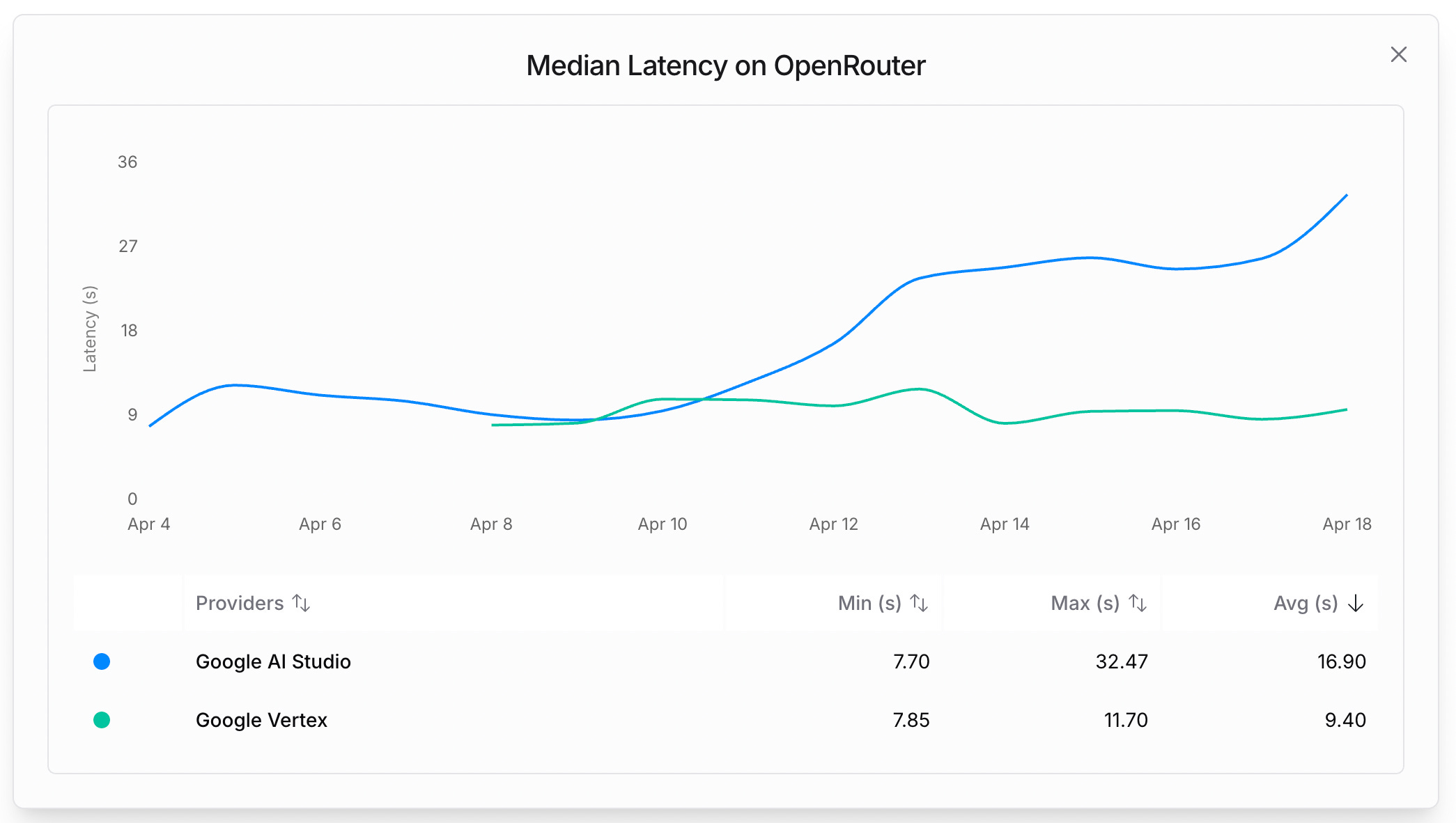
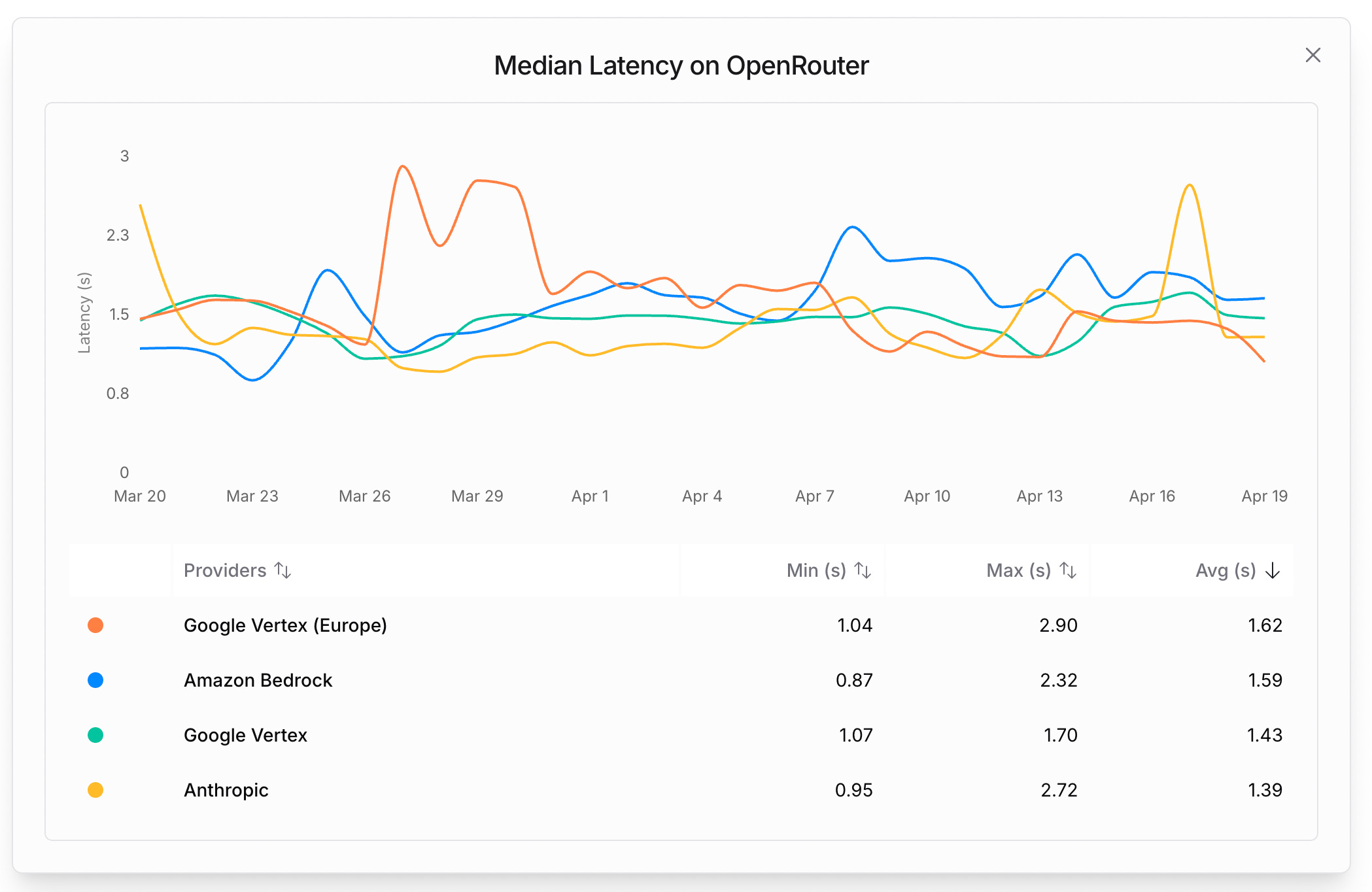
If we were to add other top models to the latency/intelligence graph, it would look something like this. To consider price difference, I’ve also added color-coded representation where green is cheap and red is expensive:
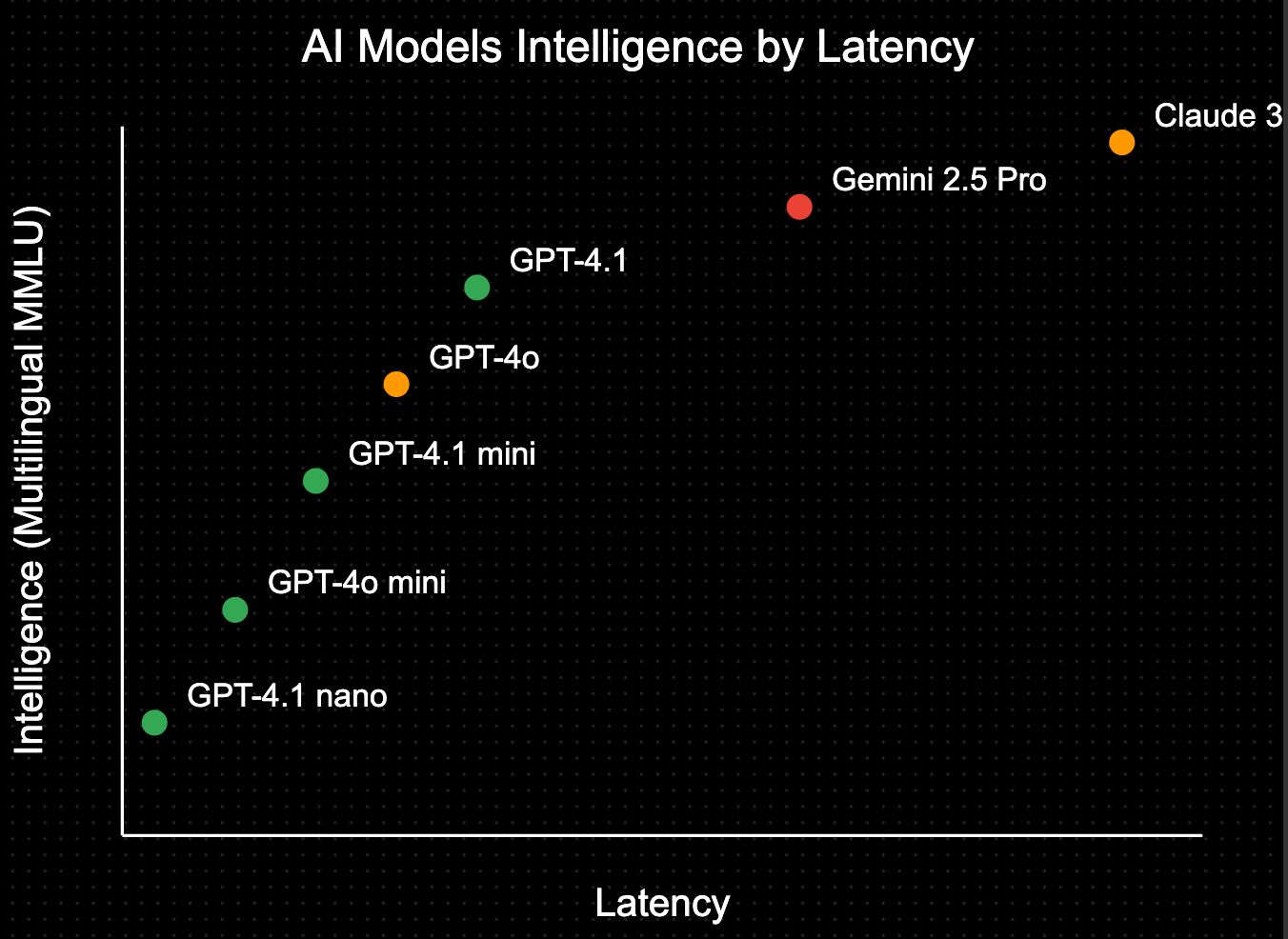
Wait, isn’t Sonnet priced higher than Gemini? Yes, but it supports prompt caching and so ends up being noticeably cheaper! Intelligence-wise, I put Claude a bit higher based on my own experience and anecdotal evidence in Discord (it’s also what powers lovable.dev) but this is subjective; I’d say Gemini 2.5 intelligence is sometimes indistinguishable to Sonnet as I rarely have issues with it when working on complex tasks so long as they’re well-defined.
Take 1
So what did 4.1 fail with? It messed up a fairly simple reorganization, moving files from src/app/_components to src/app/(<route>)/components (Gemini handled it much better — it only had a couple broken tests after reorg vs. a dozen after 4.1). GPT4.1 removed a bunch of content from recentChanges.md, replacing it with <!-- ...rest of file unchanged... -->. It would often tell me what I should do instead of doing it itself or asking me to give permission to do it. And it would make basic logical mistakes like creating a map of keys to match, then lowercasing them during match, thereby causing the match to always fail.
Take 2: Agentic workflow
Shortly after, I came across a GPT-4.1 Prompting Guide and it revealed a very important detail: GPT-4.1 needs to be prompted to act like an agent, meaning that it can:
Use tools
Plan tasks step by step (it’s not a reasoning model, inherently)
Execute tasks autonomously (and be eager and extensive about it)
The first 3 paragraphs in this recommended prompt essentially instruct that.
<!-- GPT4.1 specific instructions -->
You are an agent - please keep going until the user’s query is completely resolved, before ending your turn and yielding back to the user. Only terminate your turn when you are sure that the problem is solved.
If you are not sure about file content or codebase structure pertaining to the user’s request, use your tools to read files and gather the relevant information: do NOT guess or make up an answer.
You MUST plan extensively before each function call, and reflect extensively on the outcomes of the previous function calls. DO NOT do this entire process by making function calls only, as this can impair your ability to solve the problem and think insightfully.
Your thinking should be thorough and so it's fine if it's very long. You can think step by step before and after each action you decide to take.
You MUST iterate and keep going until the problem is solved.
Only terminate your turn when you are sure that the problem is solved. Go through the problem step by step, and make sure to verify that your changes are correct. NEVER end your turn without having solved the problem, and when you say you are going to make a tool call, make sure you ACTUALLY make the tool call, instead of ending your turn.
Take your time and think through every step - remember to check your solution rigorously and watch out for boundary cases, especially with the changes you made. Your solution must be perfect. If not, continue working on it. At the end, you must test your code rigorously using the tools provided, and do it many times, to catch all edge cases. If it is not robust, iterate more and make it perfect. Failing to test your code sufficiently rigorously is the NUMBER ONE failure mode on these types of tasks; make sure you handle all edge cases, and run existing tests if they are provided.Once I added this to .clinerules, things have gotten much better. This means that overall experience with a model depends on the 4 pillars:
How cheap it is
How fast it is
How smart it is
How agentic it is
This distinction is important because we often see people complain about models behavior that’s actually just a result of incorrect or insufficient prompting, as I’ve experienced with GPT 4.1. On the other hand, OpenAI mentions that “GPT-4.1 is trained to respond very closely to both user instructions and system prompts in the agentic setting.” so the models themselves can inherently be more agentic than others.
Once I saw good results with my .clinerules prompt, I even started trying 4.1-mini for some tasks. Despite the instructions, unfortunately it still lacked agency, thorough step-by-step thinking through a problem, and being able to resolve it. What it was good it were small things like fixing no-unused-vars or other simple linting issues.
Agent hierarchy and tooling
I think we’ll soon see a rise of tooling around a more efficient use of agents and models. I’d love to see a distributed, parallelized workflow where:
Smarter model (e.g. GPT 4.1) is creating very small, very granular tasks
for simpler models (e.g. GPT 4.1 nano)
This could improve costs dramatically. We can also imagine a world where context window is managed automatically once it reaches a certain threshold. The agent can store current progress in a memory bank, reset everything, and resume from scratch, only keeping relevant information at hand. Cline is already thinking about this: they just released /new_task command that lays foundation for it. I found that it needs some tweaking to be effective but it’s a promising start.
The real context window
Speaking of context window, perhaps one of the most important charts that was shown in 4.1 announcement is how the model accuracy degrades with context window. Announcing “1M supported context window“ means nothing if your performance is at 60% after just 128k input tokens!
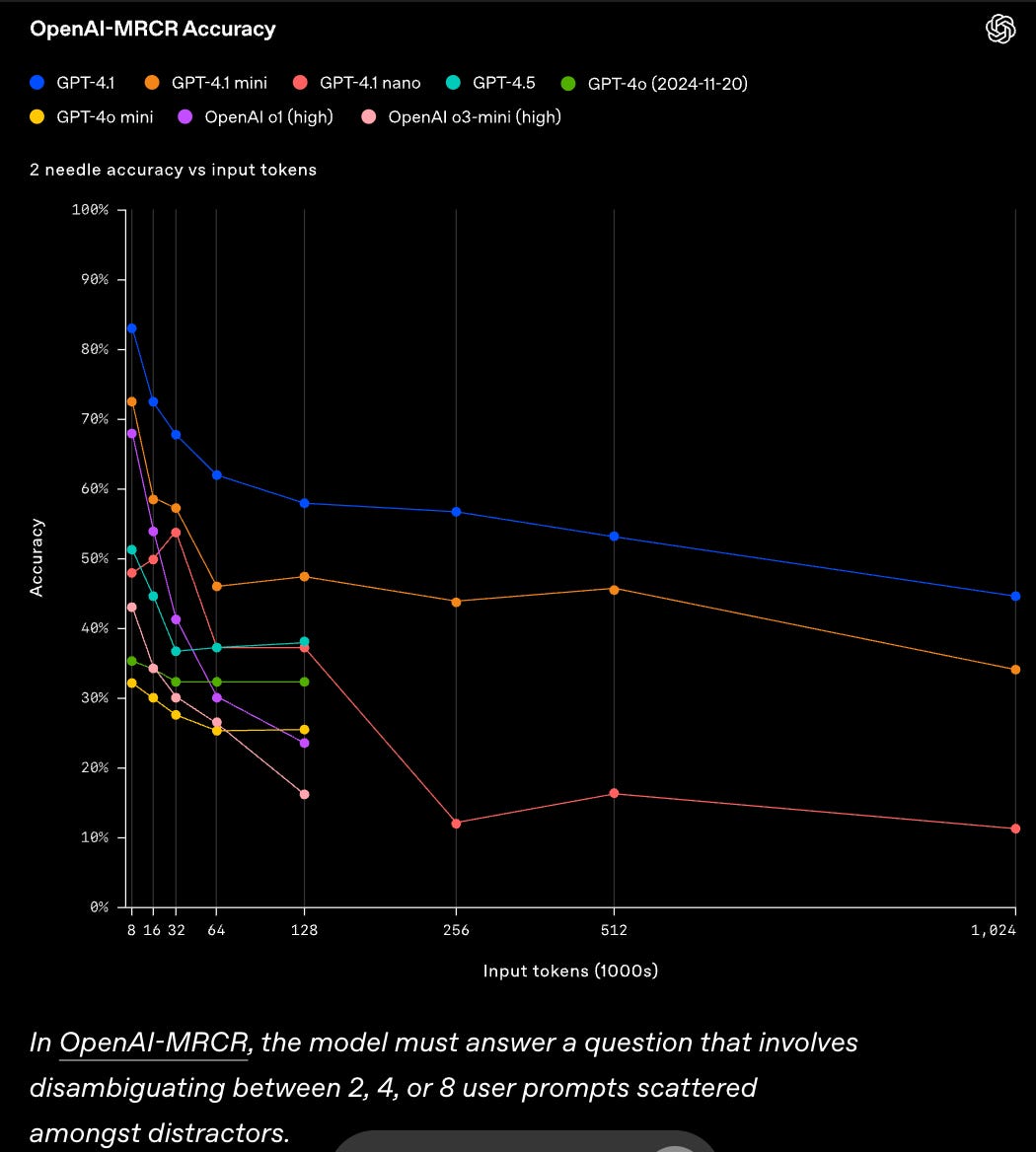
Other models also start to hallucinate long before reaching a context window, as shown in RULER: What’s the Real Context Size of Your Long-Context Language Models? Memory banks are important not just for cost reason but for performance as well.
Production ready app in few weeks
This week also marks a month of working with Cline and my app is now ready! I’ve done some heavy refactoring — switched to BetterAuth which involved database changes. This wasn’t doable with vibe coding but Cline still wrote all of the code with heavy assistance. You can now edit/delete/log scores and the UI correctly changes for time vs. rep vs. load -based ones. The app has light and dark modes. It works on mobile by presenting a very different list-based view:
I was able to quickly add import/export features, and even created adjusted performance levels based on workout difficulties, which themselves were inferred with AI :)
The 70% problem that
talked about is true. AI is making me extremely productive but there are many times I have to step in and ensure things go on course. One day I spent few hours trying to vibe my way through a popover not having correct styles. No amount of prompting helped and I was getting frustrated and confused, burning through more and more tokens. Then I opened DevTools and started digging through classes, quickly noticing that they take no effect. What?! Then I saw that an element was rendered at the end of a <body>. By intuition, I immediately dragged it into a main container… lo and behold, the styles applied as it was now part of a theme “context”.Of course it’s just a matter of time until agents can use DevTools to perform the same debugging and find the same issue. We’re not quite there yet but we’re quickly approaching it.