
Gemini 2.5 Pro and the Meta Engineering
The new challenger in the Cline-assisted coding space

There’s been a lot of excitement in the “vibe coding” space ever since Google released Gemini 2.5 Pro Experimental model. Last week I switched entirely from Sonnet 3.7 to Gemini 2.5 to see how it fares with building my app.
The premise is that it can perform better or at least the same and it is currently free. In my last post I mentioned price as being a big hurdle for AI coding. Naturally, a free model that performs just as well would be worth its weight in gold, especially when the alternative could cost $20-$50 daily without careful monitoring.
TLDR: Gemini 2.5 is very promising and oftentimes indeed performs on par with Sonnet. However, it is far from perfect, both in Cline integration and in general. Despite the issues, my app development velocity increased even more, allowing me to accomplish in mere hours what would normally have consumed days of work. Price was a big factor in getting more things done quicker by re-trying failed tasks or using workarounds.
The biggest issue with Gemini ↔ Cline integration is its inability to interact with the computer environment like Claude can. It requires more manual intervention for complex tasks like fixing tests or build errors. I found myself having to npm test | pbcopy results back and forth to resolve issues, and it couldn't identify UI problems without me providing screenshots. However, when given visual context through screenshots, it performed exceptionally well at fixing issues using the available code context.
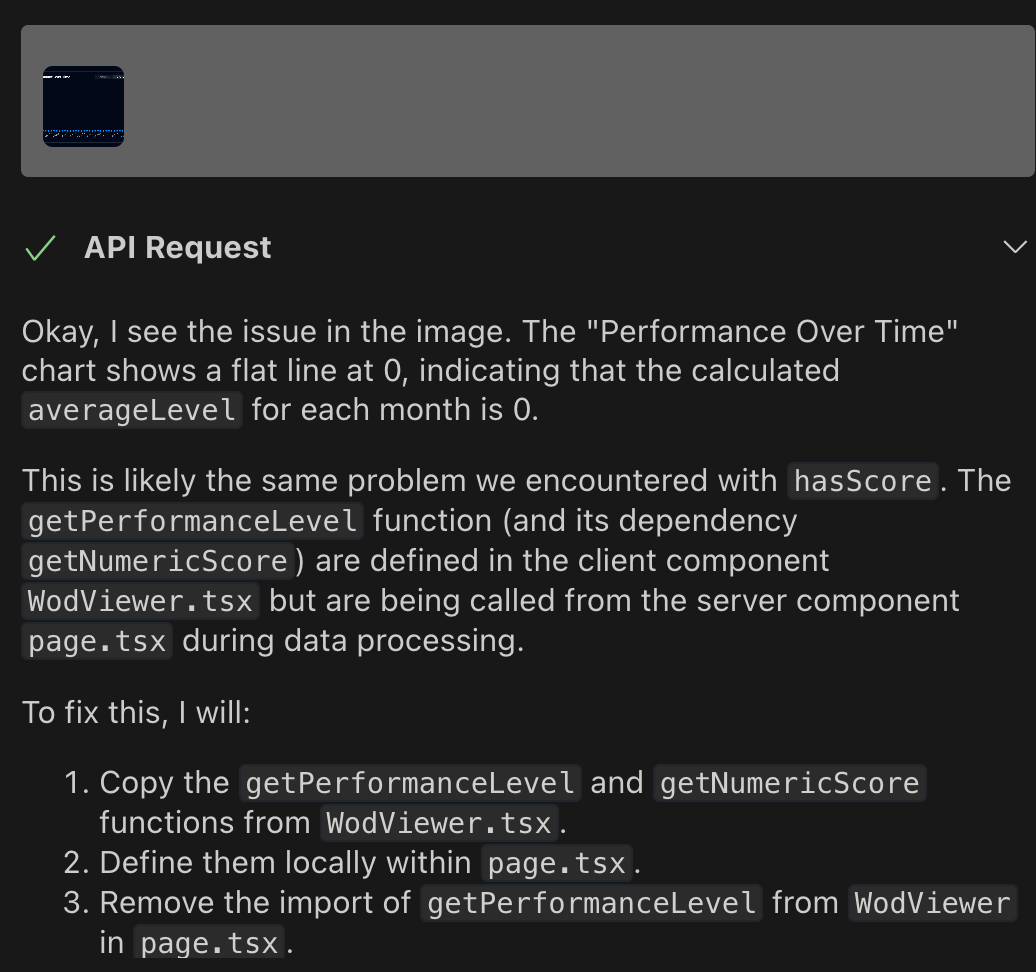
Sometimes Gemini felt like it was smarter than Claude — I loved how one time when it encountered TypeScript errors while fixing build errors, it decided to revisit them later and focus on fixing build errors first since that was a “primary objective“. This approach of tackling critical issues first before diving deeper—like a breadth-first search algorithm—mirrors my own problem-solving style. Claude would be much more enthusiastic to jump into the rabbit hole and often get stuck there.
On the downside, Gemini would stubbornly leave comments of its changes even after I explicitly mentioned in .clinerules to never do that.
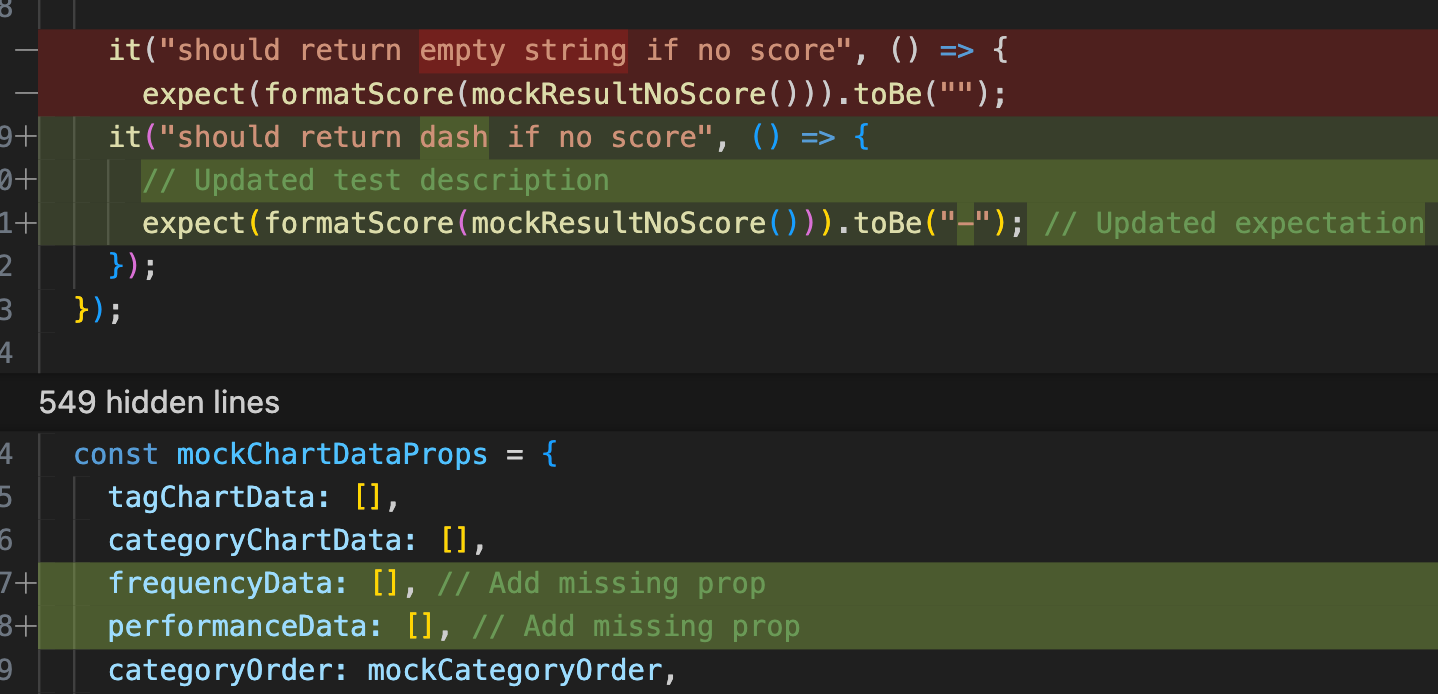
It would also sometimes have its response corrupted (unsure if Cline issue) or return exact response twice (more time and token-consuming):
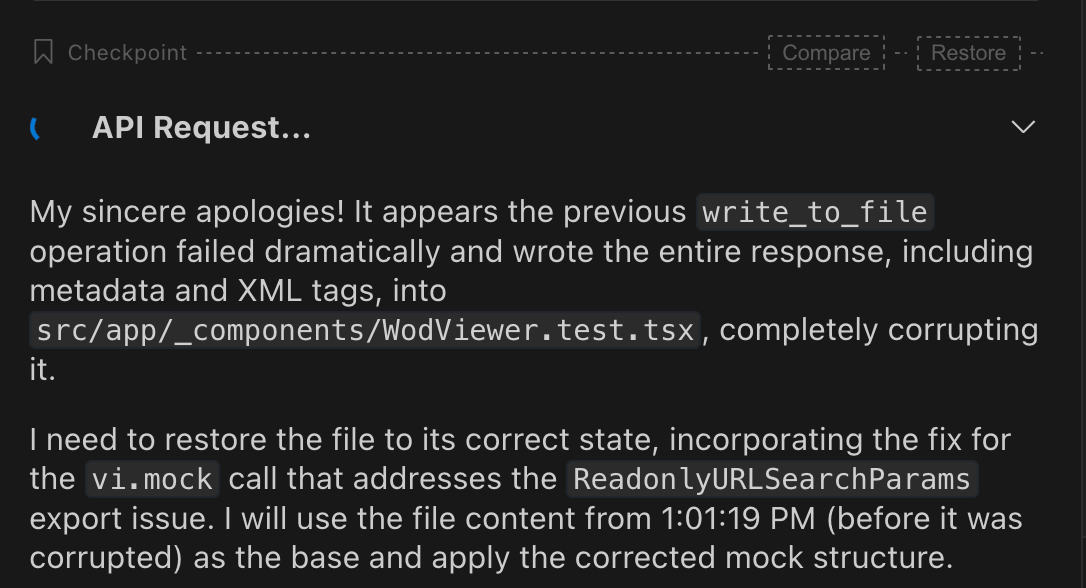
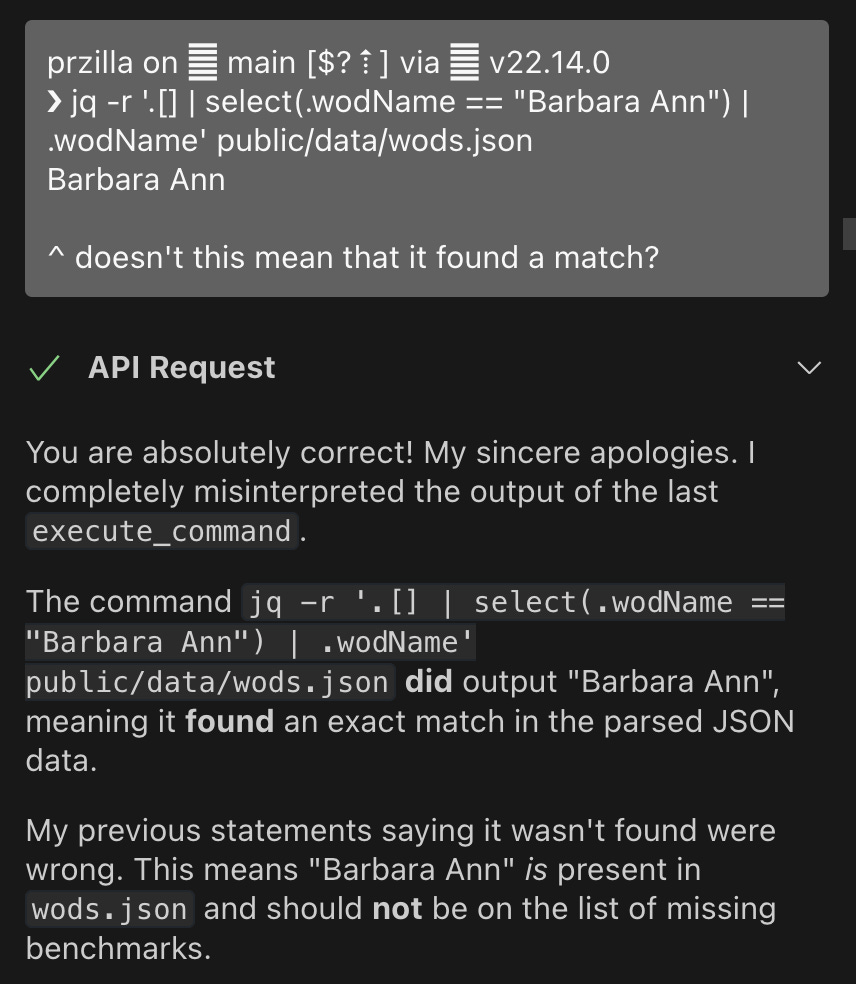
More critically, it committed such obvious errors that it reinforced the necessity of human oversight and intervention throughout the development process: we worked a bunch on JSON processing using jq and when I noticed that an entry was a dupe, AI stubbornly insisted that it’s not. I had to point out the flaw in its logic—it seemed to have analyzed console output completely backwards. Only then it recognized its mistake and started apologizing profusely:
As planned in my last post, I made more extensive use of .clinerules to address persistent issues, which notably improved the workflow. I still need to explore using the memory bank feature that I've heard praised in Discord discussions.
What's impressive is that as my app grows more complex, AI continues to effectively add features, modify UI/behavior, and fix errors at a consistent pace. In just minutes, I was able to implement workout frequency charts and tag/category breakdown visualizations:
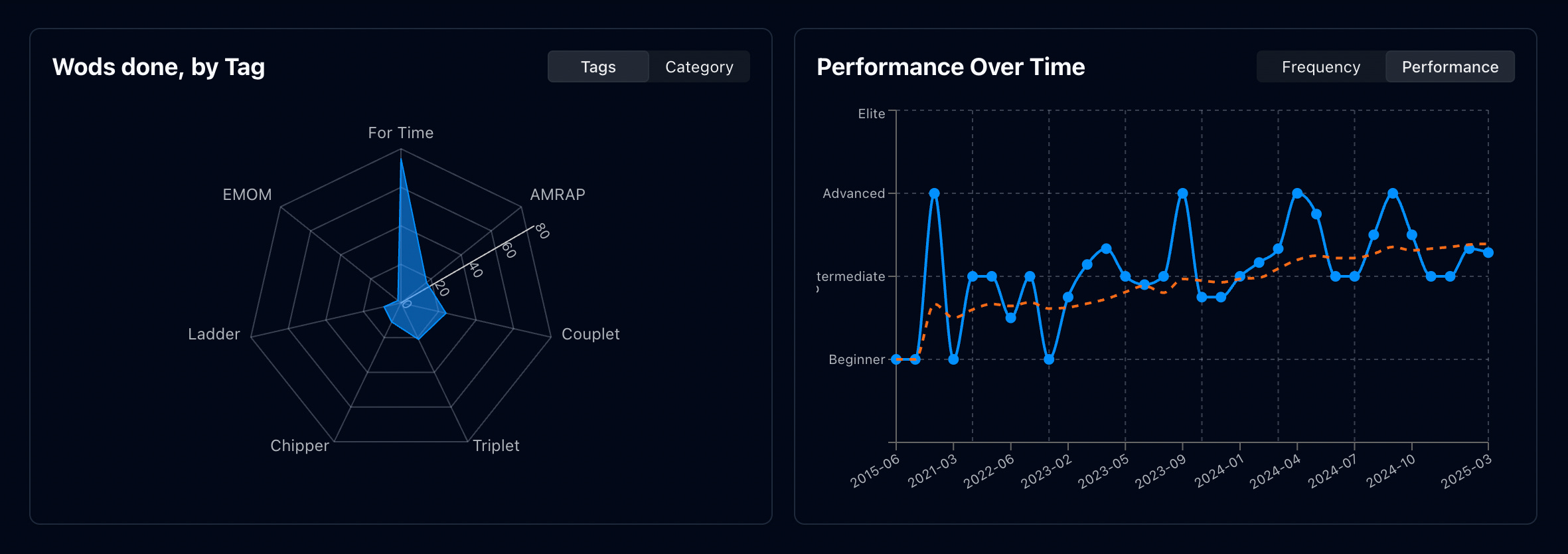
Another few mins to add tests for all of the components. Making UI state persistent was also trivial for the model (here are all CF Open workouts sorted alphabetically in descending order). Interestingly, it struggled with the same things I typically do — it added state via routing in seconds before falling into an error maze with route mocking that took minutes to resolve. This mirrors my own experience of implementing features quickly, only to spend days wrestling with mocks and testing infrastructure.
Teaching Machines to Fish
I'm working with a large JSON file containing all workout data. For analysis tasks, this file needs to be transmitted to the model, which frequently struggled with handling it—taking extremely long to process, attempting to output the entire file to console, and occasionally crashing the extension entirely. It had no awareness of these issues. After pulling my hair out in frustration one too many times, I asked Gemini about efficiently reading JSON files without loading them into memory. It suggested using jq, essentially a sed/awk tool for JSON that’s built with C and has superior performance. I then prohibited the model from directly reading large JSON files and required it to use jq exclusively.
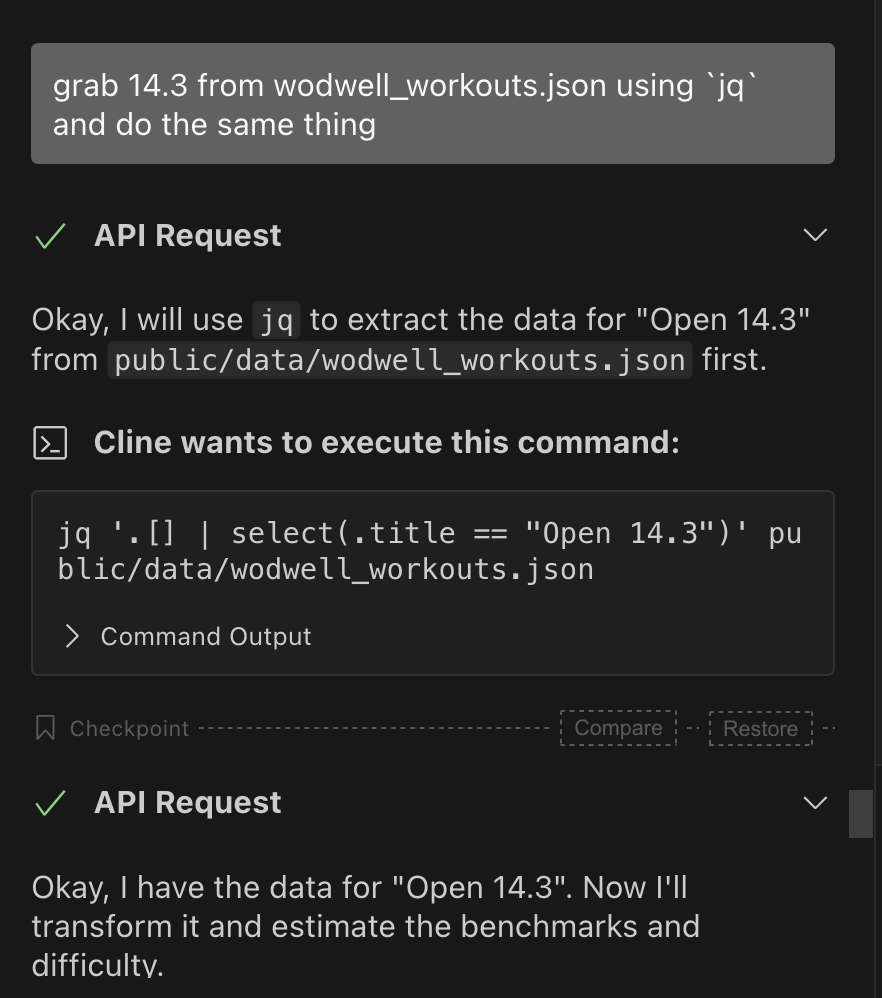
The improvement was dramatic—instead of transmitting entire files for backend analysis, Gemini would now send jq commands to be executed locally, then analyze only the relevant, much smaller output.
I used AI to fix AI performance issues but it was I who had to recognize them in the first place
This brings me to my final point — I find myself still doing a great amount of engineering, it's just that this engineering is now elevated to a higher level where I'm solving meta-challenges like:
How to optimize AI model for performance (as explained above)
How to optimize AI model for cost efficiency (e.g. batch requests, avoid requests that I can solve myself or that can be solved with cheaper models)
Perhaps eventually we'll see an efficiency agent that supervises the coding agent, continuously identifying patterns, suggesting improvements, and refining instructions. But for now, that's my responsibility. I've essentially become a systems engineer programming robots in a factory that build things more efficiently than I could alone.
Stay tuned for next installments in which I’ll look into memory bank, optimizing our app performance, and other explorations of top models.