
Building an app with Cline, Claude and Co.
Part 1. General thoughts on the experience through early stages of an app.

Inspired by Addy’s post on using Cline for AI engineering I spent this week playing around with AI-assisted app building. Below are my initial thoughts on Cline, experience with various models, and AI engineering in general. I’m hoping to make this into a series of posts as I add more features to an app and experiment with new LLMs.
In short, Cline is a mediator between AI model and VSCode. The power comes from not only a full contextual awareness of your repo— a big boon on its own—but the fact that it can run commands, read console output, and even check browser for results of its work.
Working with Cline feels a lot like something in between:
Pair programming with another engineer letting them drive coding while you’re mostly talking and suggesting.
Being a PM and telling your engineer very specific requirements of an app.
So how effective is it? Does it work? Is the coding now instinct and the 10x engineer dream a reality?
Models matter
Turns out the answer is highly dependent on the model used. As mediator, Cline itself works really well. However, the difference between using Claude Sonnet 3.7 and Gemini 2.0 can feel like talking to a senior engineer with 10 years of experience and talking to someone who started coding last week and forgets to close a bracket of a function body.
So far I’ve tried Deepseek, Gemini, Claude for a variety of tasks and only Claude’s Sonnet feels like you can actually get things done fast and correctly. Both Gemini1 and Deepseek hallucinated so bad that component files would end up with a wildly-broken JSX. AI would then desperately try to fix things only to end up with more issues, then attempting to `git reset` and losing all the history that wasn’t pushed to remote; I had to `git reflog` a bunch of commits in panic.
When it works, it truly feels like magic. You can go from a sentence like “Let's update our UI in accordance to the changes made in wods.json (see file attached)“ to it working through a problem until the very end:
Now I have a good understanding […]
Now I need to examine the UI components […]
I need to update the sortWods function […]
I need to update the WodTimeline.tsx component […]
[…rewires props, rewrites a handful of components, updates TS definitons…]
Now that I've updated all the components […] let's test the application
[…runs server and checks output…]
I need to fix the TypeScript errors in […]
I notice there's a small issue in the formatScore function […]
The Prompt-Implementation Gap
Notice I said “when it works“. Two biggest issues you’ll notice are:
AI doing the wrong thing
AI doing the “right” thing but doing too much of it
The 2nd point can likely largely be mitigated by Cline's custom instructions. For example, Claude always ran `npm run dev` at the end of a task, wanting to ensure changes look good, even though I already had Next.js server running. When I saw localhost:3006 it was time to add a permanent instruction to .clinerules.
Similarly, when I asked Claude to add sorting of a table column, not only did it implement the usual sorting by clicking on the table header, but it also added a whole new UI element. This “made sense“ to AI because the column showed attempts as “Score (date 1) → Score (date 2) → Score (date 3)“ and I asked it to sort it by number of attempts, so “Score → Score“ would go before “Score → Score → Score“. Because we didn’t show actual number of attempts, it ended up helpfully prepending it on each line: “(3) Score → Score → Score“ or “(1) Score“.

This isn’t UI I imagined or even considered. Such surprising interpretations can be equally useful and frustrating.
You probably realize by now that there’s actually no “doing the wrong thing“ or “doing too much“. This is a problem of mapping the look and behavior we imagine to a concrete implementation in code. Using a lossless format like natural language will always leave room for deviation.
This is why prompt engineering often feels like art but two things should make development easier:
Creating an extremely detailed description of UI/UX
Working within carefully curated frameworks
The 2nd point is interesting in that it essentially forces AI to operate within a narrower context: if we’re using Radix UI with a dark theme, and you ask Claude to add a toggle, it’s smart enough to use SegmentedControl and it will be dark because the theme simply won’t allow it to look otherwise2.
AI can only mess things up as much as your building blocks will allow it to
The 1st point is something we’ll have to figure out with time but folks already experiment with some fascinating markdown -driven development as Reuven Cohen writes here. I started experimenting with this but it’s hard to figure out just how specific you have to be and which things can be omitted. I’m reminded of how before Agile came around, we had waterfall development; at my first software engineering job circa 2007, we were given 100-page long, detailed design documents of all states of an app. Have we come full circle?
From Coding to Creating
The app I’m building isn’t very complex but the current UI still took me few days. Am I really 10x more productive? Or am I spending the same amount of time fixing AI hallucinations and struggling to figure out correct prompts?
Looking back, I haven’t written 95% of the code in the repo. Despite corrections and reverts, the speed at which I’m able to add features, iterate on UI, fix errors, and perform larger refactoring is probably 5x comparing to manual work. I spent 1-2hr each day on changes that would otherwise take me 4-5hr.
It’s a strange feeling to not have to write code, especially since those thornier problems are what brings the most joy (and tears), having spent hours solving them as you advance through stages of confusion, rage, and acceptance. While it feels empowering to be able to add features that you have gaps in understanding of, it also seems like a missed opportunity to learn them. But is the goal to learn or to create? The focus shifts heavily to the latter.
AI-assisted engineering feels like swimming a whole layer above the abstraction you’re so used to. The things I found as blockers were mostly design -related and so I spent most of the time tweaking UI and figuring out best way to present the data and interaction with that data:
Beyond 10x
In the recent commentary on how “90% of code will be written by AI in the next 3 months“, Theo argues that having intuition to figure out a complex problem among many layers of a system is something AI can’t solve. Yet, I’ve observed both Claude and Gemini 2.5 (arguably an even better model), reason through an error as a staff-level engineer would, considering multiple angles based on context that are far from obvious, attempting to solve them, then isolating issues and reasoning further based on what worked and what didn’t in previous steps, eventually narrowing down and solving them.
While root causes can be quickly identified by a human via intuition, you’re unlikely to catch up to AI with refactoring. More data is needed to determine how well this works in large, real-life apps but it’s looking promising. I explained to Claude what changes were made to the underlying JSON and it rewrote 5 non-trivial functions, changed 3 components, and updated all TS definitions in seconds rather than minutes. Now we’re talking way more than 10x speed.
The Cost of AI Excellence
The latest models certainly feel like a panacea but what’s the catch? I loaded up Claude with $20 worth of credits and ran out of all of them in just 2 days.
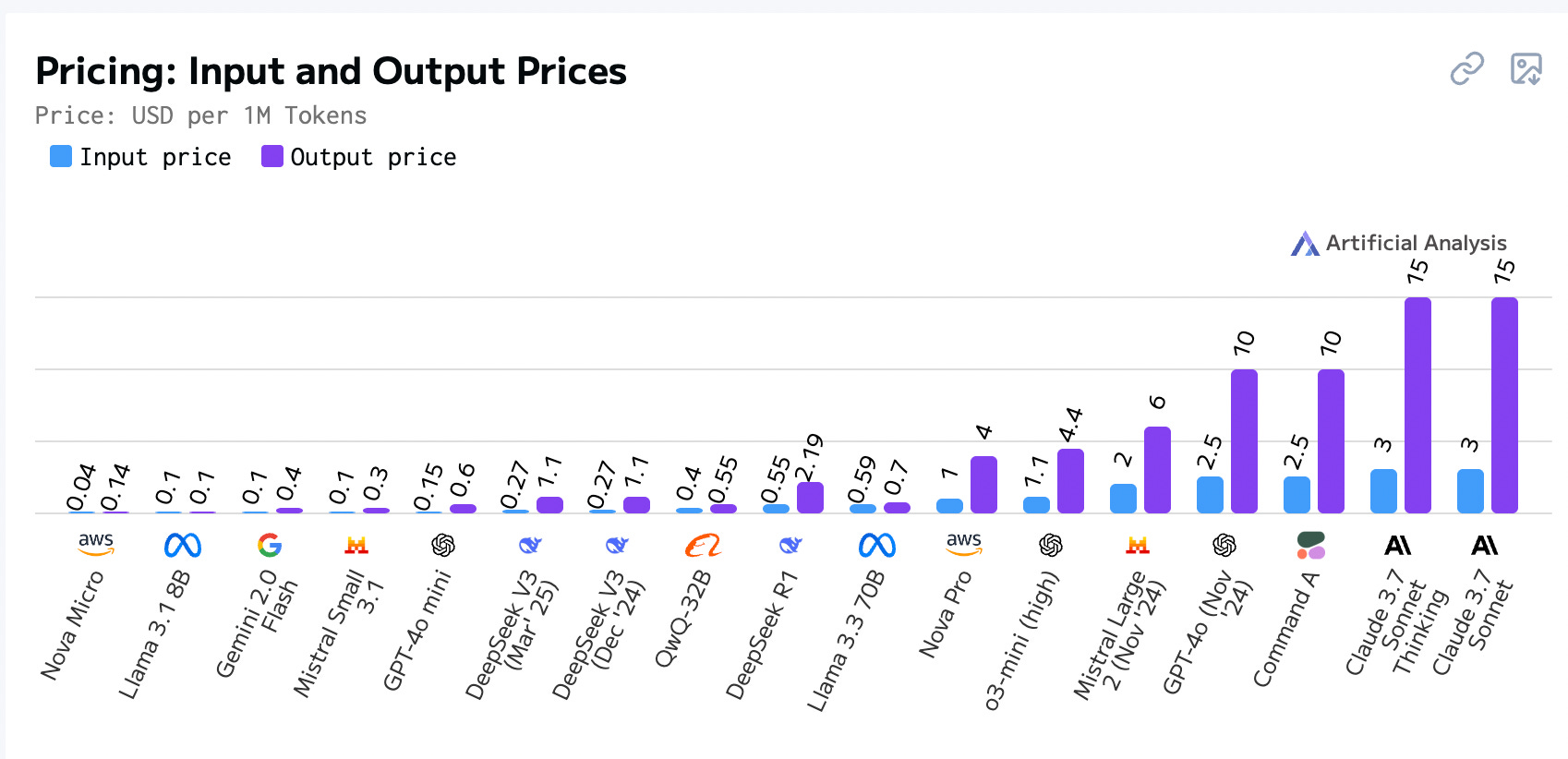
Simple tasks—by virtue of having large context window and often having to send large volume of output tokens—are usually somewhere between $0.5 and $1. As you’re iterating on your task, the counter keeps climbing up — $3.40… few mins later, $6.75. If you don’t pay attention, couple hours later you’re close to $20.
This isn’t a terribly lot of money, but it’s not insignificant. For comparison, DeepSeek is so cheap that you never have to worry about cost at all.
DeepSeek R1: $0.14 / million tokens for input, $0.55 / million tokens for output
Claude 3.7 Sonnet: $3 / million tokens for input, $15 / million tokens for output
Addy suggested to use DeepSeek for planning and Sonnet for acting, and it certainly helps, but even that approach can quickly rack up costs. And here’s the thing — the numbers might seem high but when it comes to saving engineer time that measures in $100+/hour, even Sonnet pricing is a… pretty affordable option.
Anthropic is likely aware of this which explains why their pricing tiers haven’t budged in recent months. We’ll see if the competition from a recent release of Gemini 2.5 drives these lower.
Next steps
Stay tuned for future installments. Some things I’d like to try:
Bridge the gap between design and code; try design mockups
Improve interpretation with custom rules
See how AI performs with more complex tasks (e.g. storing data in DB, adding users, authentication, user-level data input, etc.)
See how it fares with even larger refactoring like switching to an entirely different UI component library
Gemini 2.5 (released couple days ago) is much better but more on that later!
You can often still end up with broken colors if your AI isn’t careful with using themed tokens; something that can perhaps be clarified in the global instructions